DP17 Splitting and Summarizing String Values
Description
In the example, there is a “Reasons for Service” field that comprises the checked reasons for service each interaction had. Some are single reasons but most cases have grouped two or more reasons separated by commas. To measure the monthly impact of each reason individually, it is necessary to apply to split and summarize this data.
In order to split these values we can tally the total number of reasons for all the patients in a period, by using the base::strsplit() function. It splits the field into a list of lists. These lists are then converted into a sparse matrix to summarize them.
Link to the Complete Script in Github
R Script - Split string of values
Initial Data for the Field: Reasons for Service
For a data frame with 9355 records, let’s check the most frequent combination of “Reasons for Service”, with the most frequent values at the top and listing the top 20. For that purpose, the next code is applied:
1
2
head(dfINT %>% group_by(Reason.s..for.Service) %>% tally %>% arrange(desc(n)),20)
Table: Combination of Reasons. Top 20 most frequent.
| Reason.s..for.Service | n |
|---|---|
| Assessment,Education,Engagement,Other | 2505 |
| Post Discharge Call / Visit | 1155 |
| Care Coordination | 1048 |
| Engagement | 505 |
| Assessment,Education,Engagement | 320 |
| Assessment | 310 |
| Assessment,Engagement | 304 |
| Assessment,COVID-19 Education,Education,Engagement | 215 |
| Other | 205 |
| Assessment,Engagement,Post Discharge Call / Visit | 197 |
| Medication Management | 171 |
| Monitoring | 150 |
| Care Coordination,Education | 148 |
| Assessment,Other,Post Discharge Call / Visit | 110 |
| Education,Engagement | 101 |
| Education,Engagement,Monitoring | 93 |
| Assessment,COVID-19 Education,Education,Engagement,Other | 77 |
| Assessment,COVID-19 Education,Other,Post Discharge Call… | 75 |
| Engagement,Post Discharge Call / Visit | 70 |
| Education | 51 |
Combination of Reasons in the R Console
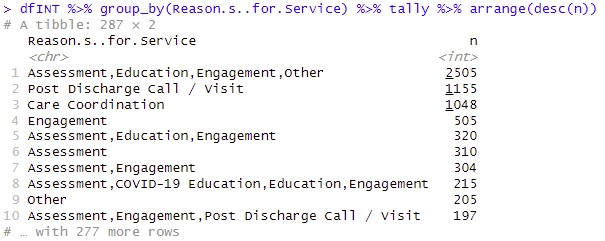 Initial Data: Reasons for Service merged with commas
Initial Data: Reasons for Service merged with commas
Add an ID Index column
dfRecapNoUTR$ID <- seq.int(nrow(dfRecapNoUTR))
Reasons for Service for the first five records
| ID | Reasons |
|---|---|
| 1 | Assessment,Education,Engagement,Other |
| 2 | Assessment,Other,Post Discharge Call / Visit |
| 3 | Post Discharge Call / Visit |
| 4 | Assessment,Education,Engagement,Other |
| 5 | Assessment,Education,Engagement,Other |
Getting List of Lists
The next step involves splitting the string values into multiple columns using the strsplit function, using comma as separator.
1
dat <- with(dfRecapNoUTR, strsplit(Reason.s..for.Service, ',')) # Result: List of Lists
List of Lists for first five records
 Partial Results: List within List for first 5 records
Partial Results: List within List for first 5 records
Unlisting the values and relating them with the corresponding ID they belong to
The index ID is repeated for each reason in the record as many times as the number of reasons within the record:
1
2
3
df2 <- data.frame(ID = rep(dfRecapNoUTR$ID,
times = lengths(dat)),
Reason.s..for.Service = unlist(dat))
Resulting Unlisted Reasons by ID
| ID | Reason.s..for.Service |
|---|---|
| 1 | Assessment |
| 1 | Education |
| 1 | Engagement |
| 1 | Other |
| 2 | Assessment |
| 2 | Other |
| 2 | Post Discharge Call / Visit |
| 3 | Post Discharge Call / Visit |
| 4 | Assessment |
| 4 | Education |
| 4 | Engagement |
| 4 | Other |
| 5 | Assessment |
| 5 | Education |
| 5 | Engagement |
| 5 | Other |
Create a table ID ~ Reasons
1
2
3
4
# Sparse Matrix. Convert table to data frame
df3 <- as.data.frame(cbind(ID = dfRecapNoUTR$ID,
table(df2$ID, df2$Reason.s..for.Service)))
head(df3)
Resulting Sparse Matrix
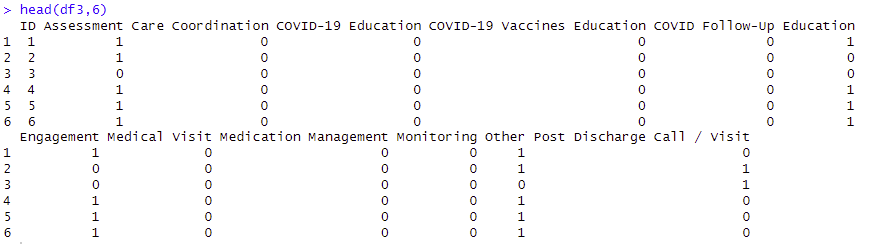 Result: Sparse Matrix
Result: Sparse Matrix
Joining the sparse matrix to the main data and Recap per Year ~ Month
1
2
3
4
5
6
7
dfRecapReasons <- dfRecapNoUTR %>% select("YearMonth", "ID") %>%
inner_join(df3, by = 'ID')
dfRecapReasons <- data.table(dfRecapReasons %>%
group_by(YearMonth) %>%
select(-c("ID")) %>%
summarise_all(list(sum)))
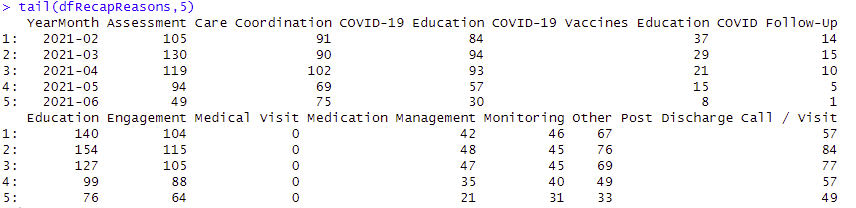 Result: Summarized values
Result: Summarized values
__
End of Post